如何理解BP算法:从错误中学习,在传递中进化(一)
如何理解BP算法:从错误中学习,在传递中进化
这个话题我们分为两部分,在「一」中我们主要讨论基础的反向传播和梯度下降原理。
- 初步理解:梯度和反向传播
- 反向传播要解决什么问题,是如何实现的
在「二」中我们将围绕梯度下降中出现的问题,对BP算法的发展演化做更具体的了解,从而对参数更新方法有更整体的了解。
- 梯度下降中的常见问题
- BP算法的演化
初步理解:梯度和反向传播
首先我们尝试感性地理解反向传播。
在「基础的深度神经网络—从多层感知机开始」中了解神经网络的基本结构和特性后,很可能会好奇数据是如何在网络中流动的,这么复杂的网络是如何学习到能够适应环境的参数w?为什么一个静态的网络能够动起来学习到数据中的信息,这就不得不说到信息在神经网络中的流动的两种方向:前向传播和后向传播;
首先「正向传播」很好理解,顾名思义是指特征数据输入到网络后,数据与w和b产生计算,随着层层输出和处理,最终得到输出的结果y;而「反向传播」(BP:Backpropagation)则是把这个过程反过来,从最终的损失函数值出发,通过链式法和沿着梯度方向则将后一步的损失分摊到前一层的参数上,直到分摊到所有参数上;
为什么反向计算,就能算出合适每个神经元的参数呢?首先我们从一次正向传播的结束出发,我们得到了一个预测值和真实值的差,也就是损失函数的差;这个值可以看做是环境数据对目前神经网络学习的反馈和评估,那么我们该如何利用这个反馈来倒逼网络结构参数的优化呢?
换言之,为了下一次预测更准确,网络中的每个神经元该怎么调整?一种符合直觉的预想是根据每一个神经元对最终偏差的贡献大小进行调整:贡献大的神经元我们多调整一些,贡献少的神经元我们少调整一些;但是如何来计算每个神经元对偏差的贡献呢?
如果计算对偏差贡献实数值,是很难的;因为目前通过一次正向传播,我们只能看到一个静态的网络,每个感知机(神经元)只有一个参数和输入的x、和输出的y,我们很难说y里面有多少是贡献给了最终偏差的部分,更难计算参数w有多少贡献给了最终偏差的部分;如果解决这个问题,我们就需要引入「梯度」的概念。
当然,如果有一些微积分基础,这个问题就很好理解了,不过我们可以不管它,先尝试用我们的生活经验对梯度有一个直觉性的理解。
如果我们只有一个静态数据,但是我们却要预测一个运动物体下一秒的状态时,我们就会引入速度的概念;比如下面这个狂野的女司机,有了速度的概念,尽管你看到的是一张静止的图,但是通过画面中模糊方向的线索,你却能生出下一步运动状态如何的意识(比如轮子大概率会被逆时针旋转)。这里的”速度”实际上就是一种”梯度”,这就是对于「梯度」非常直觉性的理解了。

一个静态视觉的例子
梯度下降
感受到了梯度,比如我们知道图中方向盘逆时针方向旋转的角度代表了损失值,看起来目前我们得到一个比较大的损失值。我们如果想缩小这个损失,就要尽可能的将方向盘向逆时针方向调整,包括女司机双臂的姿势都向着反向调整,每一个细节的调整方向都是不同维度的梯度下降,最终我们就会得到一个方向盘下一秒看起来不太可能逆时针转动的图像,即根据我们的调整预期下一秒的损失值缩小了。我们继续沿着梯度下降最大的方向调整,缩小损失函数的参数优化方向,这个过程就是我们常说的通过梯度下降优化损失函数。
链式法则和反向传播
回到一开始,我们是通过反向传播这样的方式实现了梯度下降的计算,你一定也会问,为什么反向计算就能够计算出梯度?
偏导和梯度的关系是什么呢?
偏导实际上描述了每个节点的输出值和该节点每个维度变量的关系,固定x不变,y变化,输出z也会变化;这实际上表达了损失函数变化对每个维度变量变化的敏感度(损失函数微小变化/某个维度变量对应的微小变化),偏导就是用来准确的描述这个关系。比如这个节点上一共有x,y两个维度,那么同理z和x的偏导数也是一样。这样我们先分别对z求不同维度上自变量的偏导数。
然后把这个两个偏导数的向量相加,我们就得到了z的梯度;可以直接记住这个关系:z梯度=∑偏导向量。
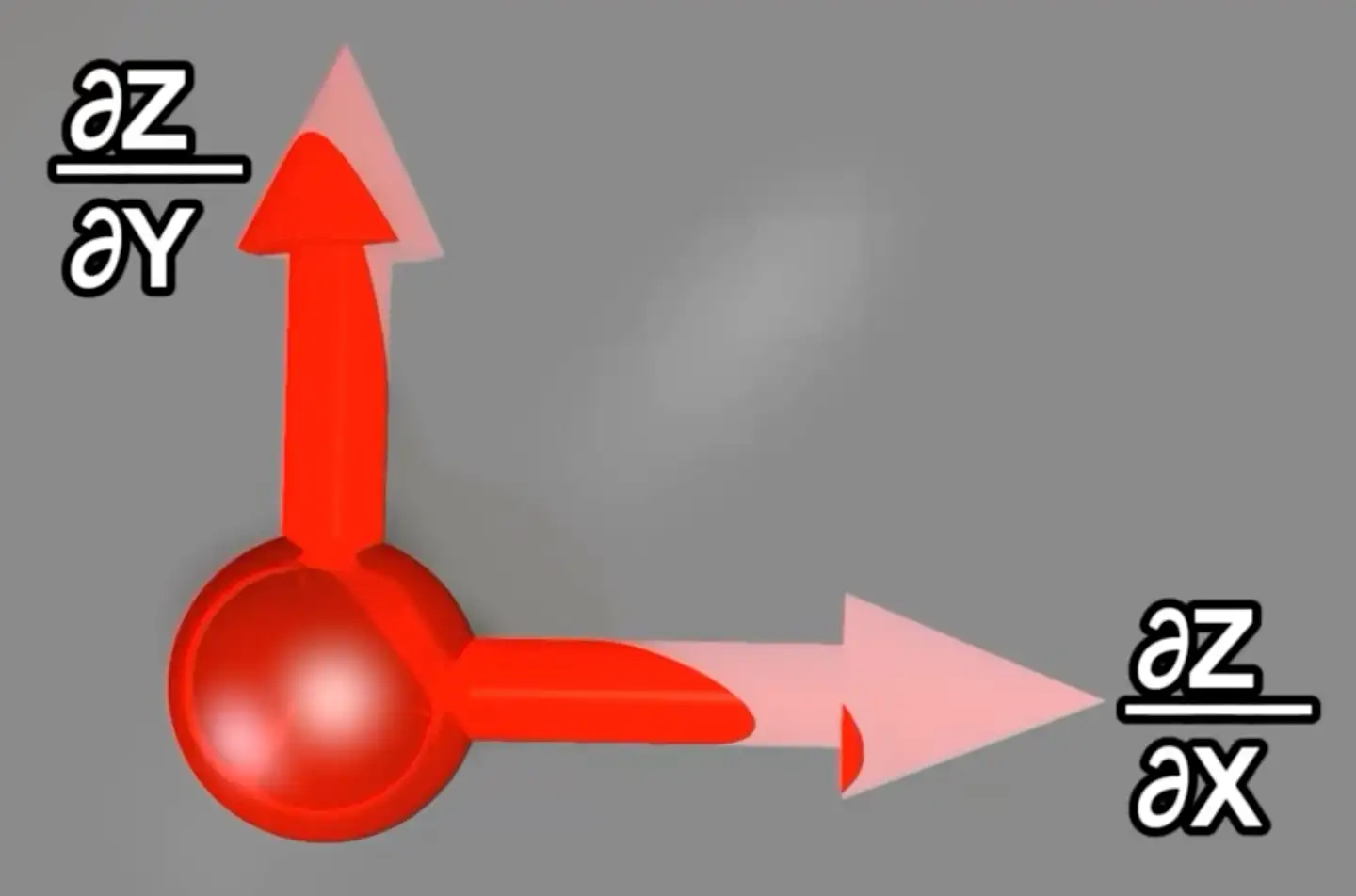
在一个点上对不同维度求偏导的向量和就是梯度:z梯度=∑偏导向量
当我们的任务是对全局的E 逐个节点去求偏导,将偏导数相加得到梯度做出每一节点的改进;我们似乎找到了解法,但是如何落地呢,复杂的网络是如何实现求偏导的计算呢?
我们下面以某一个神经元节点的视角来看链式法则逐层分解的过程。对于每一个感知机来说,它只需要关注上游传递下来的 E 对本节点输出的偏导(∂E/∂z),并进行节点内局部梯度的计算(∂z/∂x , ∂z/∂y),就可以通过链式法则得到一个新的 E对下一个节点的偏导,如此自后向前传递,直到第一层输入的节点完成一次BP传播。网络中每个节点在进行反向传播时,都只考虑与其直接相连的节点即可,只需要求该节点的偏导向量和就可以得到该节点参数的优化方向;

计算图中的任意一个节点
梯度更新
反向传播时计算最终损失函数(偏差的信息)对变量 a 的偏导(▽ L),将总的损失分摊到每一层的每一个神经元的参数w和b上(▽ L),根据每个参数对损失的影响大小,求出损失减少的梯度方向,相应的承担修改的责任,得到本次优化和迭代的方向,即每一次学习,每个影响点都会得到当前状态对损失函数的贡献是否正向,并会得到及时的矫正,梯度更新的通式为:W = W - η* ▽ L
nebula L:表示损失函数L的梯度,nebula形如▽
η:学习率
W:更新前和更新后的参数
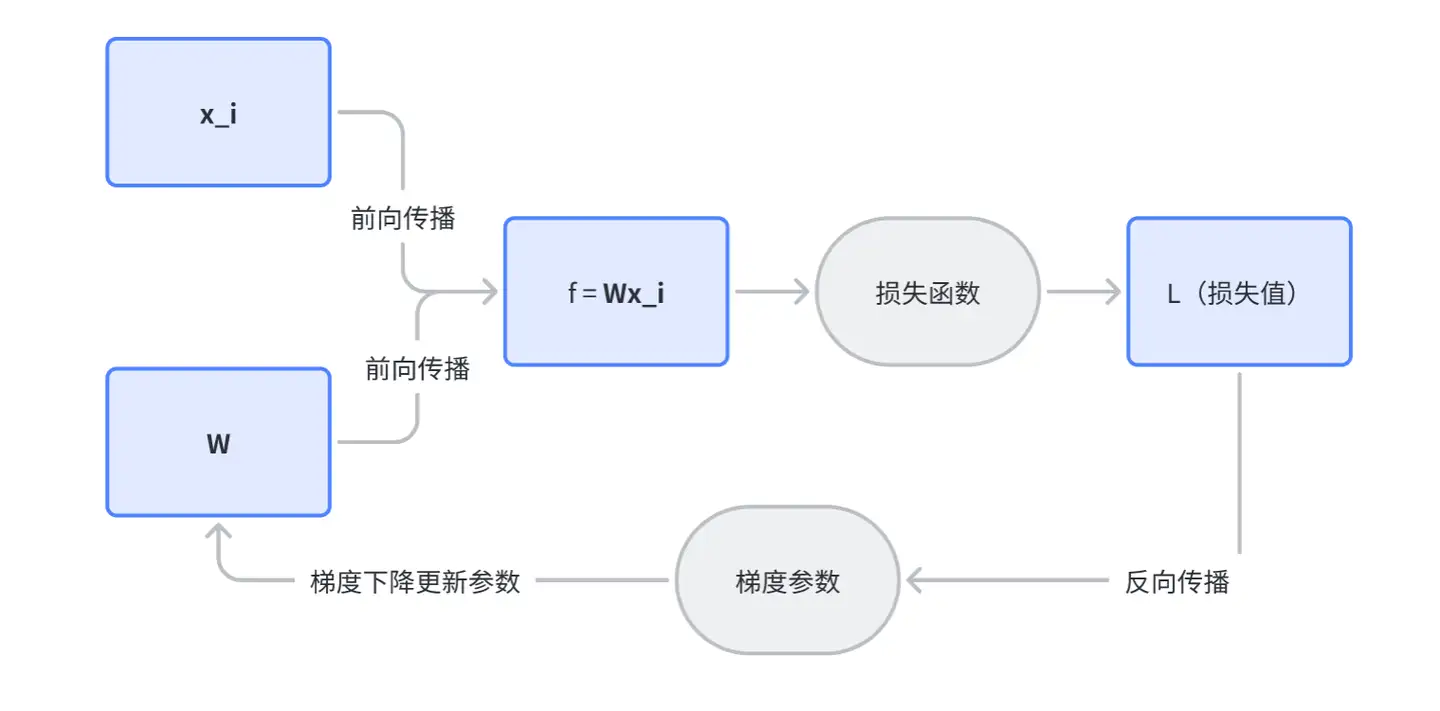
线性分类器中的反向传播和梯度更新
总结一下,关于反向传播梯度更新算法的几个特点:
高效性:基于链式法则的反向传播将复杂网络求梯度变成了相连节点的递归运算,每个节点只需要处理同样的局部求梯度计算,并且只关注和它最近邻的节点回传的信息,这给从硬件层面高效计算的解决方案提供了可能;
可叠加性:反向传播时与A节点相连的所有节点梯度值在A处叠加,叠加值代表了A处节点对于损失函数的杠杆大小;
高维度:梯度向量和原向量的维度相同,每一个节点的每一个参数都会有一个梯度,梯度向量的每个元素表示该特定元素对最终函数error的影响大小;(在进阶篇会通过网络的数学符号化表达,尝试具体的感知参数矩阵的大小;)
反向传播算法本质上是一个让网络结构和外界环境关联起来的反馈系统,梯度下降法是一种具体的更新策略,使用梯度信息实现参数的更新。把学习问题转化成了最优化问题,能够让每一个神经元(感知机节点)向着可能优化的方向不断变化并得到激励反馈的机制。也就是让网络动起来,让数据塑造神经网络的一种方法。需要注意的是在使用时,为了保持这种反馈链接的存在,反向传播要求神经元(节点)的激励函数可微。